Load and call query modules
The following page describes how query modules are loaded into Memgraph and called within a Cypher query.
If you require more information about what query modules are, please read the query modules overview page.
Loading query modules
Once you start Memgraph, it will attempt to load query modules from all *.so
and *.py files from the default (/usr/lib/memgraph/query_modules and
/var/lib/memgraph/internal_modules) directories.
MAGE modules are located at
/usr/lib/memgraph/query_modules and custom modules developed via Memgraph Lab at
/var/lib/memgraph/internal_modules.
Memgraph can load query modules from additional directories, if their path is
added to the --query-modules-directory flag in the main configuration file
(/etc/memgraph/memgraph.conf) or supplied as a command-line parameter (e.g.
when using Docker).
If you are supplying the additional directory as a parameter, do not forget to
include the path to /usr/lib/memgraph/query_modules, otherwise queries from
that directory will not be loaded when Memgraph starts.
When working with Docker and memgraph-platform image, you should pass
configuration flags inside of environment variables, for example:
docker run -p 7687:7687 -p 7444:7444 -p 3000:3000 -e MEMGRAPH="--query-modules-directory=/usr/lib/memgraph/query_modules,/usr/lib/memgraph/my_modules" memgraph/memgraph-platform`
If you are working with memgraph or memgraph-mage images you should pass
configuration options like this:
docker run -p 7687:7687 -p 7444:7444 memgraph/memgraph --query-modules-directory=/usr/lib/memgraph/query_modules,/usr/lib/memgraph/my_modules
If a certain query module was added while Memgraph was already running, you need
to load it manually using the mg.load("module_name") procedure within a query:
CALL mg.load("py_example");
If there is no response (no error message), the load was successful.
If you want to reload all existing modules and load any newly added ones, use
mg.load_all():
CALL mg.load_all();
If there is no response (no error message), the load was successful.
You can check if the query module has been loaded by using the mg.procedures()
procedure within a query:
CALL mg.procedures() YIELD *;
Calling query modules
Once the MAGE query modules or any custom modules you developed have been loaded into Memgraph, you can call them within queries using the following Cypher syntax:
CALL module.procedure([optional parameter], arg1, "string_argument", ...) YIELD res1, res2, ...;
Every procedure has a first optional parameter and the rest of them depend on the procedure you are trying to call. The optional parameter must be result of the aggregation function project(). If such a parameter is provided, all operations will be executed on a projected graph. Otherwise, you will work on the whole graph stored inside Memgraph.
Each procedure returns zero or more records, where each record contains named
fields. The YIELD clause is used to select fields you are interested in or all
of them (*). If you are not interested in any fields, omit the YIELD clause.
The procedure will still run, but the record fields will not be stored in
variables. If you are trying to YIELD fields that are not a part of the
produced record, the query will result in an error.
Procedures can be standalone as in the example above, or a part of a larger query when we want the procedure to work on data the query is producing.
For example:
MATCH (node) CALL module.procedure(node) YIELD result RETURN *;
When the CALL clause is a part of a larger query, results from the query are
returned using the RETURN clause. If the CALL clause is followed by a clause
that only updates the data and doesn't read it, RETURN is unnecessary. It is
the Cypher convention that read-only queries need to end with a RETURN, while
queries that update something don't need to RETURN anything.
Also, if the procedure itself writes into the database, all the rest of the
clauses in the query can only read from the database, and the CALL clause can
only be followed by the YIELD clause and/or RETURN clause.
If a procedure returns a record with the same field name as some variable we
already have in the query, that field name can be aliased with some other name
using the AS sub-clause:
MATCH (result) CALL module.procedure(42) YIELD result AS procedure_result RETURN *;
Managing query modules from Memgraph Lab
You can inspect query modules in Memgraph Lab (v2.0 and newer). Just navigate to Query Modules.
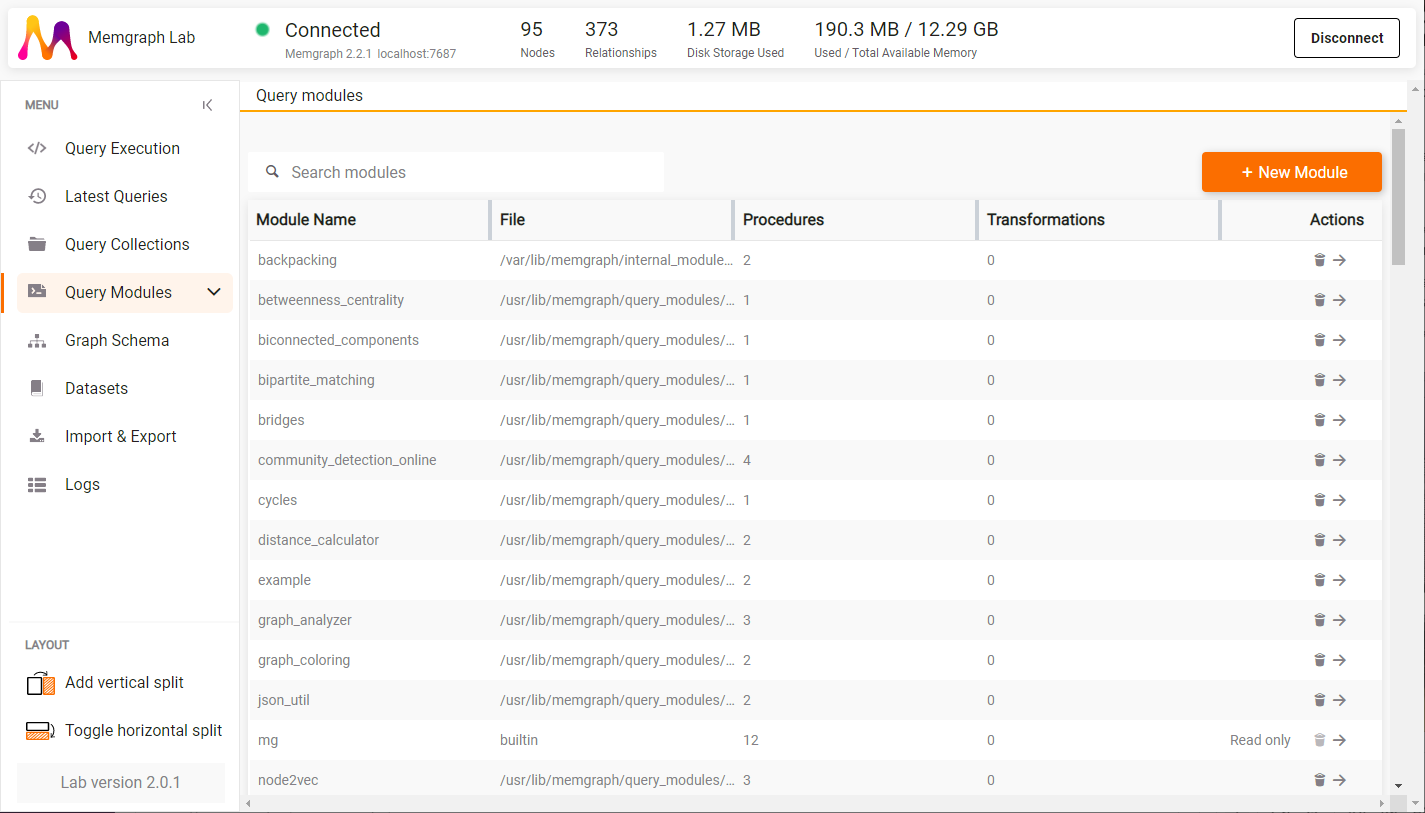
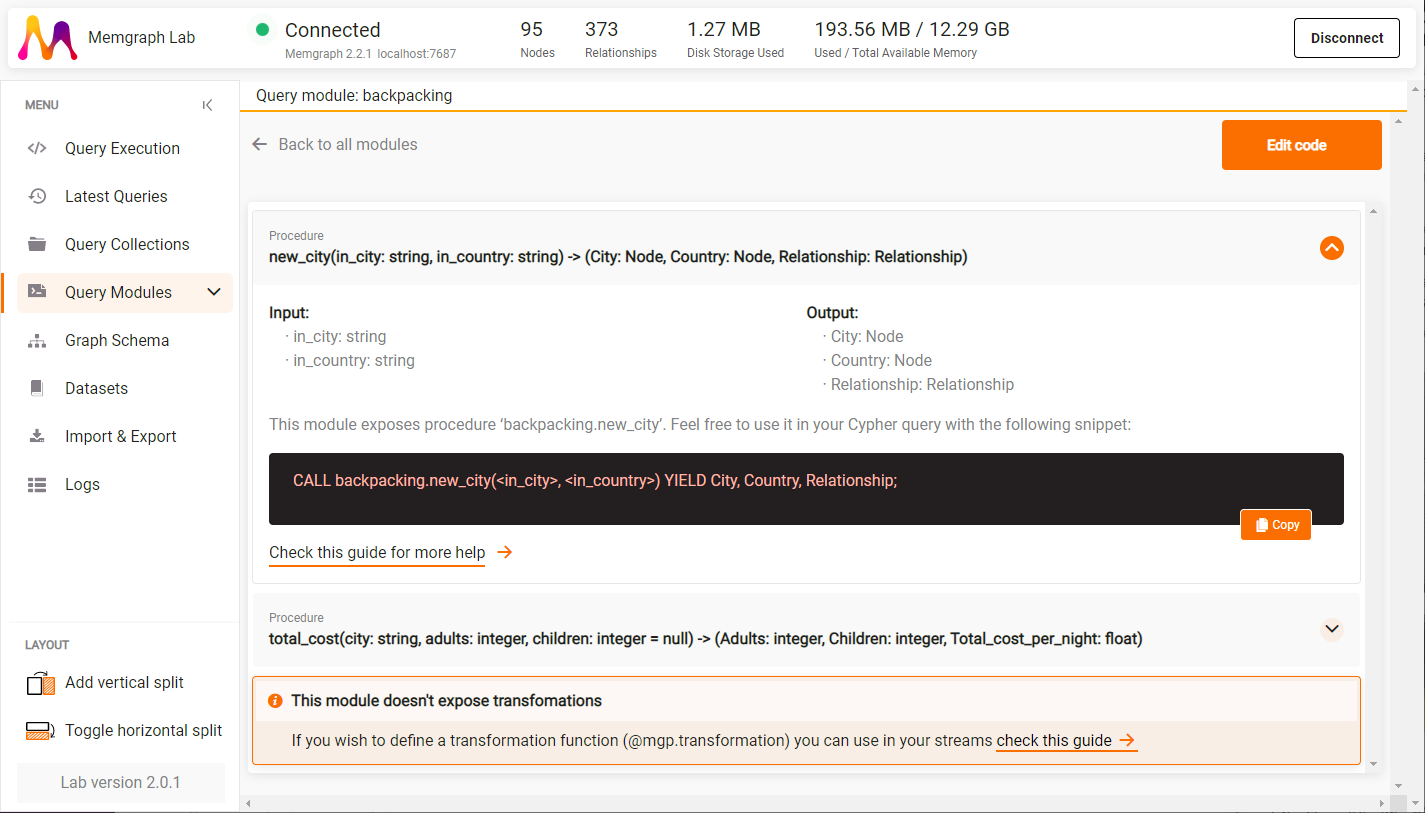
There you can see all the loaded query modules, delete them, or see procedures and transformations they define by clicking on the arrow icon.
By expanding procedures you can receive information about the procedure's
signature, input and output variables and their data type, as well as the CALL
query you can run directly from the Query Modules view.
Custom modules developed via Memgraph Lab are located at
/var/lib/memgraph/internal_modules.
Controlling procedure memory usage
When running a procedure, Memgraph controls the maximum memory usage that the
procedure may consume during its execution. By default, the upper memory limit
when running a procedure is 100 MB. If your query procedure requires more
memory to yield its results, you can increase the memory limit using the
following syntax:
CALL module.procedure(arg1, arg2, ...) PROCEDURE MEMORY LIMIT 100 KB YIELD result;
CALL module.procedure(arg1, arg2, ...) PROCEDURE MEMORY LIMIT 100 MB YIELD result;
CALL module.procedure(arg1, arg2, ...) PROCEDURE MEMORY UNLIMITED YIELD result;
The limit can either be specified to a specific value (either in KB or in
MB), or it can be set to unlimited.