CSV import tool
CSV is a universal and very versatile data format used to store large quantities
of data. Each Memgraph database instance includes a CSV import tool called
mg_import_csv. The CSV import tool should be used for initial bulk ingestion
of data into the database. Upon ingestion, the CSV importer creates a snapshot
that will be used by the database to recover its state on its next startup.
If you are already familiar with the Neo4j bulk import tool, then using the
mg_import_csv tool should be easy. The CSV import tool is fully compatible
with the Neo4j CSV
format. If you
already have a pipeline set-up for Neo4j, you should only replaceneo4j-admin
import with mg_import_csv.
For more detailed information about the CSV import tool, check our Reference guide.
Importing CSV data using the mg_import_csv should be a one-time operation done
before running Memgraph. In other words, this tool should not be used to import
data into an already running Memgraph instance.
If you are using Docker, before the import, you need to transfer CSV files where the Docker container can see them.
Please check the examples below to find out how to use the import tool based on the complexity of your data.
Examples
Here are two examples of how to use the CSV import tool depending on the complexity of your data:
One type of nodes and relationships
Let's import a simple dataset.
Download the people_nodes.csv file with the following content:
id:ID(PERSON_ID),name:string,:LABEL
100,Daniel,Person
101,Alex,Person
102,Sarah,Person
103,Mia,Person
104,Lucy,Person
Download the
people_relationships.csv file with the following content:
:START_ID(PERSON_ID),:END_ID(PERSON_ID),:TYPE
100,102,IS_FRIENDS_WITH
103,101,IS_FRIENDS_WITH
102,103,IS_FRIENDS_WITH
101,104,IS_FRIENDS_WITH
104,100,IS_FRIENDS_WITH
101,102,IS_FRIENDS_WITH
100,103,IS_FRIENDS_WITH
Let's import the dataset using the CSV import tool. We will be importing 2 CSV files.
Your existing snapshot and WAL data will be considered obsolete, and Memgraph will load the new dataset. This means that all of your existing data will be lost and replaced with the newly imported data.
If your Memgraph docker is running, you need to stop it before starting the import process.
- Docker 🐳
- Linux
If you are using Docker, first copy the CSV files where the Docker container can see them:
docker container create --user memgraph --name mg_import_helper -v mg_import:/import-data busybox
docker cp people_nodes.csv mg_import_helper:/import-data
docker cp people_relationships.csv mg_import_helper:/import-data
docker rm mg_import_helper
Then, run the import tool with the following command, but be careful of three things:
- Check the image name you are using is correct:
- If you downloaded Memgraph Platform, leave the current image name
memgraph/memgraph-platform. - If you downloaded MemgraphDB, replace the current image name with
memgraph. - If you downloaded MAGE, replace the current image name with
memgraph/memgraph-mage. - If you are using Docker on Windows and execute commands in PowerShell change the line breaks from \ to `.
- Check that the paths of the files you want to import are correct.
docker run --user="memgraph" -v mg_lib:/var/lib/memgraph -v mg_import:/import-data \
--entrypoint=mg_import_csv memgraph/memgraph-platform \
--nodes /import-data/people_nodes.csv \
--relationships /import-data/people_relationships.csv
If you get a --nodes flag is required! error, the paths to the files are incomplete or you are missing them completely.
Next time you run Memgraph, the dataset will be loaded.
docker run -it -p 7687:7687 -p 7444:7444 -p 3000:3000 -v mg_lib:/var/lib/memgraph memgraph/memgraph-platform
For information on other options, run:
docker run --entrypoint=mg_import_csv memgraph/memgraph-platform --help
sudo -u memgraph mg_import_csv --nodes people_nodes.csv --relationships people_relationships.csv
Next time you run Memgraph, the dataset will be loaded.
After the import, the graph in Memgraph should look like this:
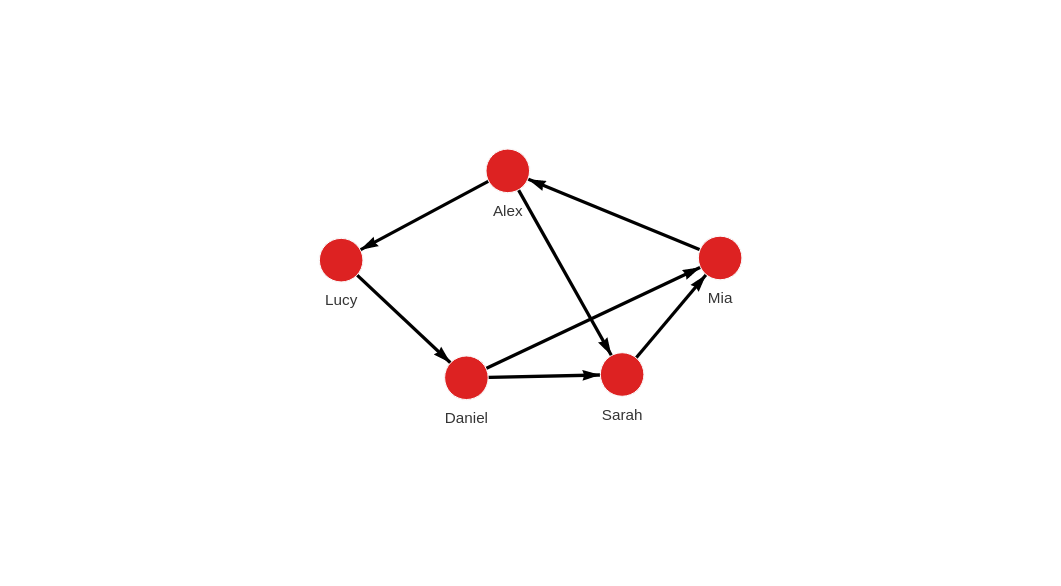
Multiple types of nodes and relationships
The previous example is showcasing a simple graph with one node type and one relationship type. If we have more complex graphs, the procedure is similar. Download the four CSV files to define a dataset:
You can check the contents of the files and its description in the tabs below.
- people_nodes.csv
- people_relationships.csv
- restaurants_nodes.csv
- restaurants_relationships.csv
The people_nodes.csv file contains the people nodes with name, age, city and label properties.
id:ID(PERSON_ID),name:string,age:int,city:string,:LABEL
100,Daniel,30,London,Person
101,Alex,15,Paris,Person
102,Sarah,17,London,Person
103,Mia,25,Zagreb,Person
104,Lucy,21,Paris,Person
105,Adam,23,New York,Person
Each person from the people_nodes.csv file is connected to at least one other person by
being friends.
In the
people_relationships.csv
file each row represents one friendship and the year it started.
:START_ID(PERSON_ID),:END_ID(PERSON_ID),:TYPE,met_in:int
100,102,IS_FRIENDS_WITH,2014
103,105,IS_FRIENDS_WITH,2021
102,103,IS_FRIENDS_WITH,2005
101,104,IS_FRIENDS_WITH,2005
104,100,IS_FRIENDS_WITH,2018
105,102,IS_FRIENDS_WITH,2017
100,103,IS_FRIENDS_WITH,2001
The restaurants_nodes.csv file introduces another node type - restaurants:
id:ID(REST_ID),name:string,menu:string[],:LABEL
200,Mc Donalds,Fries;BigMac;McChicken;Apple Pie,Restaurant
201,KFC,Fried Chicken;Fries;Chicken Bucket,Restaurant
202,Subway,Ham Sandwich;Turkey Sandwich;Foot-long,Restaurant
203,Dominos,Pepperoni Pizza;Double Dish Pizza;Cheese filled Crust,Restaurant
The restaurants_relationships.csv file defines what people ate at which restaurants:
:START_ID(PERSON_ID),:END_ID(REST_ID),:TYPE,liked:boolean
100,200,ATE_AT,true
103,201,ATE_AT,false
104,200,ATE_AT,true
101,202,ATE_AT,false
101,203,ATE_AT,false
101,200,ATE_AT,true
102,201,ATE_AT,true
Let's import 4 files using the CSV import tool.
- Docker 🐳
- Linux
If you are using Docker, first copy the CSV files where the Docker container can see them:
docker container create --user memgraph --name mg_import_helper -v mg_import:/import-data busybox
docker cp people_nodes.csv mg_import_helper:/import-data
docker cp people_relationships.csv mg_import_helper:/import-data
docker cp restaurants_nodes.csv mg_import_helper:/import-data
docker cp restaurants_relationships.csv mg_import_helper:/import-data
docker rm mg_import_helper
Then, run the import tool with the following command, but be careful of three things:
- Check the image name you are using is correct:
- If you downloaded Memgraph Platform leave the current image name
memgraph/memgraph-platform. - If you downloaded MemgraphDB replace the current image name with
memgraph. - If you downloaded MAGE replace the current image name with
memgraph/memgraph-mage. - If you are using Docker on Windows and execute commands in PowerShell change the line breaks from \ to `.
- Check that the paths of the files you want to import are correct.
docker run --user="memgraph" -v mg_lib:/var/lib/memgraph -v mg_etc:/etc/memgraph -v mg_import:/import-data \
--entrypoint=mg_import_csv memgraph/memgraph-platform \
--nodes /import-data/people_nodes.csv \
--nodes /import-data/restaurants_nodes.csv \
--relationships /import-data/people_relationships.csv \
--relationships /import-data/restaurants_relationships.csv
The next time you run Memgraph, the dataset will be loaded:
docker run -it -p 7687:7687 -p 7444:7444 -p 3000:3000 -v mg_lib:/var/lib/memgraph memgraph/memgraph-platform
For information on other options, run:
docker run --entrypoint=mg_import_csv memgraph/memgraph-platform --help
sudo -u memgraph mg_import_csv --nodes people_nodes.csv --nodes restaurants_nodes.csv --relationships people_relationships.csv --relationships restaurants_relationships.csv
The next time you run Memgraph, the dataset will be loaded.
After the import, the graph in Memgraph should look like this:
