Connect to data streams using Memgraph Lab wizard
Memgraph can natively ingest streaming data from upstream sources using Apache Kafka, Redpanda and Pulsar.
The following page instructs how to connect to data streams to ingest the data and manage the connection using a wizard in the Stream section of Memgraph Lab. If you prefer writing commands, you can also manage streams with Cypher queries.
To import data from streams using Cypher queries:
- Start Memgraph and connect to the database
- Create a stream in Memgraph
- Add a transformation module
- Start ingesting data from the stream
If you need a Kafka stream to play around with, we've provided some at Awesome Data Stream!
Create a stream in Memgraph
To add a stream in Memgraph Lab:
- Switch to Streams and Add New Stream.
- Choose stream type, enter a stream name, server address, and topics you want to subscribe to.
- Go to the Next Step.
- Click on Edit to modify the Consumer Group, Batch Interval or Batch Size.
If you are trying to connect to MovieLens Kafka data stream from the Awesome Data Stream, the stream configuration should look like this:

Once the basic configuration is finished, you need to define a transformation module and attach it to the stream.
Add a transformation module
A transformation module is a set of user-defined transformation procedures written in C or Python that act on data received from a streaming source. Transformation procedures instruct Memgraph on how to transform incoming messages to consume them correctly.
While you are creating a new stream, you can create and add a new transformation module in Python from the stream details view:
Click on Add Transformation Module.
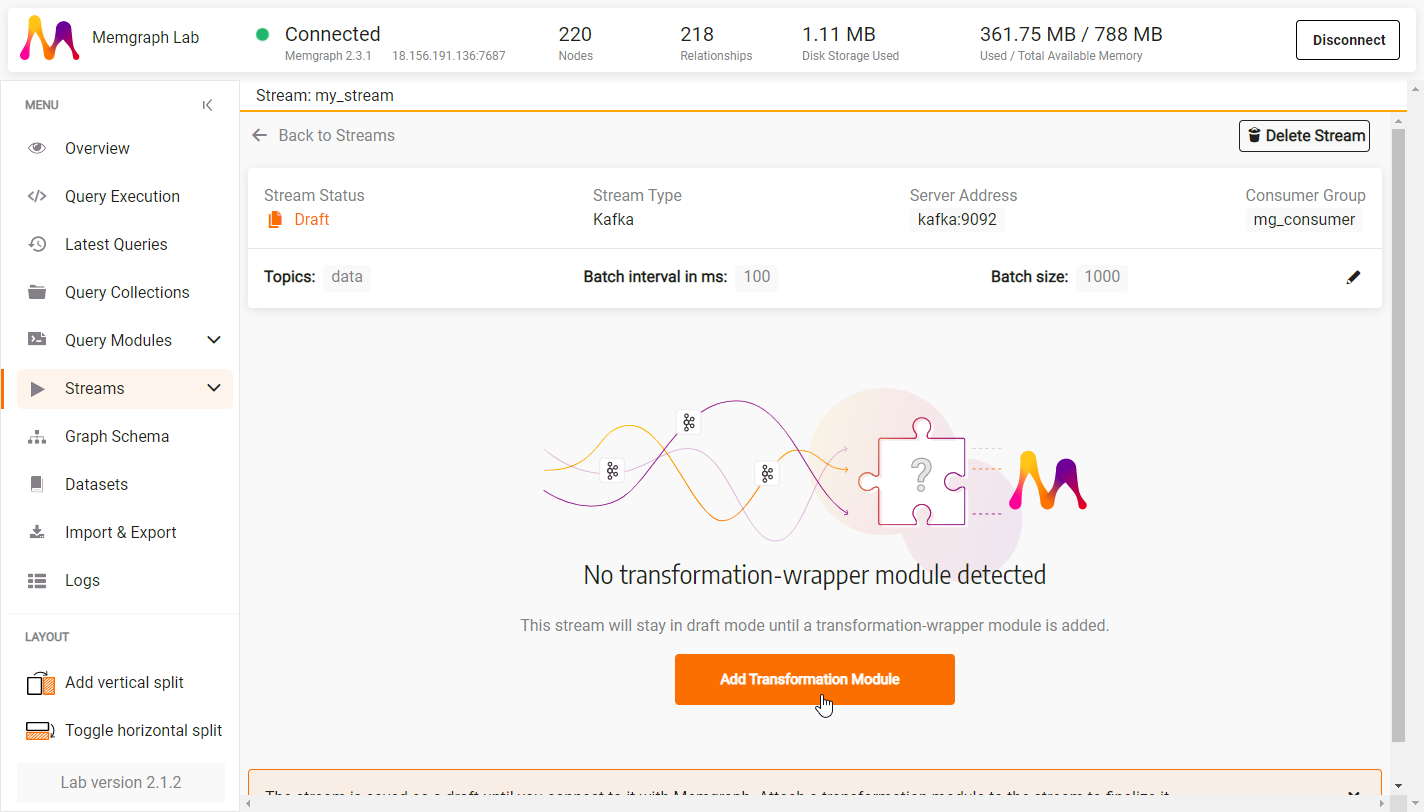
Click on Choose Transformation Module.
Select an existing transformation module, or + Create new transformation.
Review an existing module, or clear the screen and write a new transformation procedure.
Save the transformation module.
Check if the necessary transformation procedure is visible under Detected transformation functions on the right.
Select a transformation procedure and Attach to Stream.
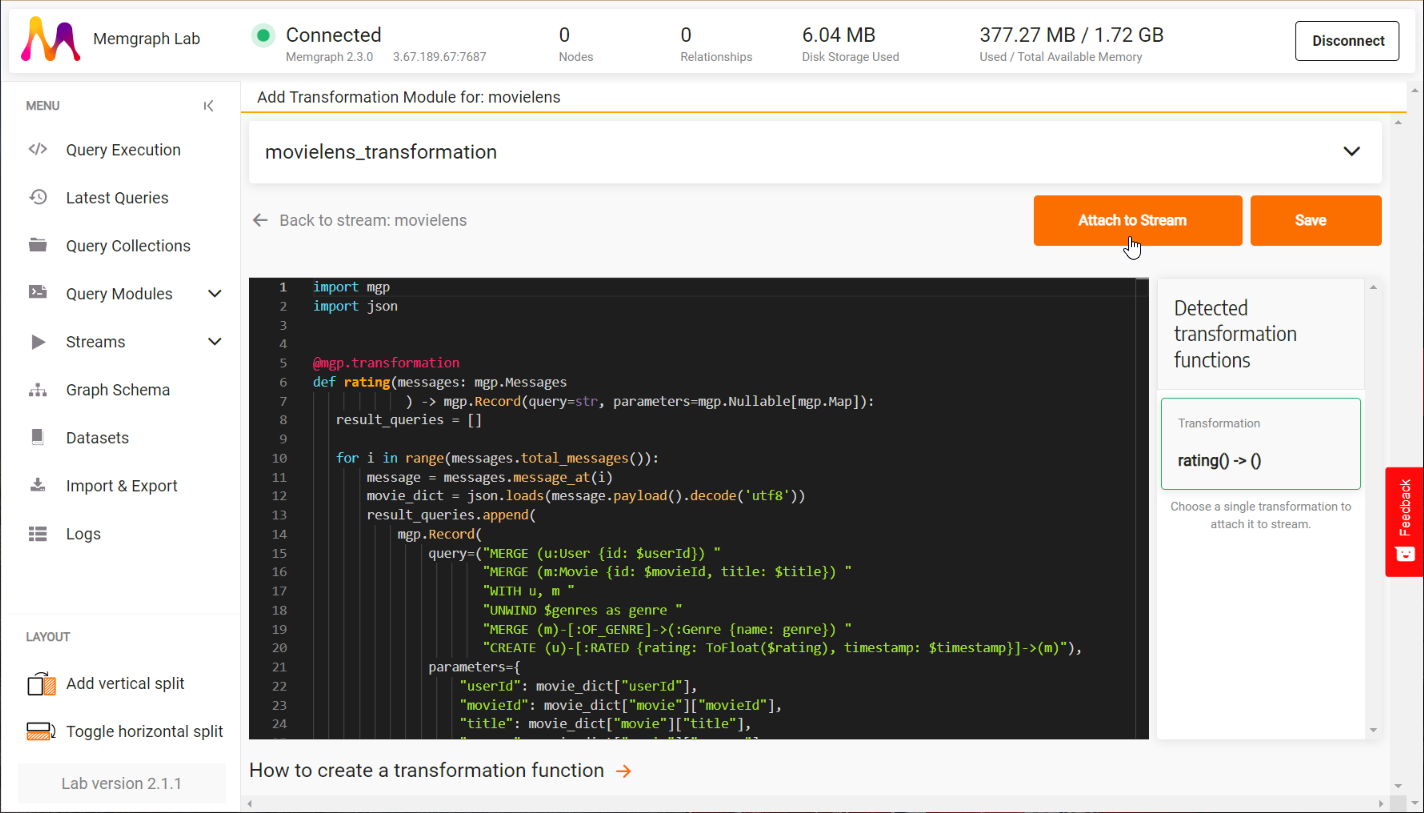
You can also develop transformation modules in Python beforehand in the section Query Modules. Click on the New Module, and the Lab will automatically recognize transformation procedures once you define them and save the module.
If you developed a procedure in C (or Python) as a separate file, you have to load it into Memgraph first, and then you will be able to see it in the Query Modules section and attach it to a stream.
Check the transformation module for MovieLens on Awesome Data Stream.
Set Kafka configuration parameters
If necessary, add the Kafka configuration parameters to customize the stream:
- In the Kafka Configuration Parameters + Add parameter field.
- Insert the parameter name and value.
- To add another parameter, Add parameter filed.
- Save Configuration once you have set all parameters.
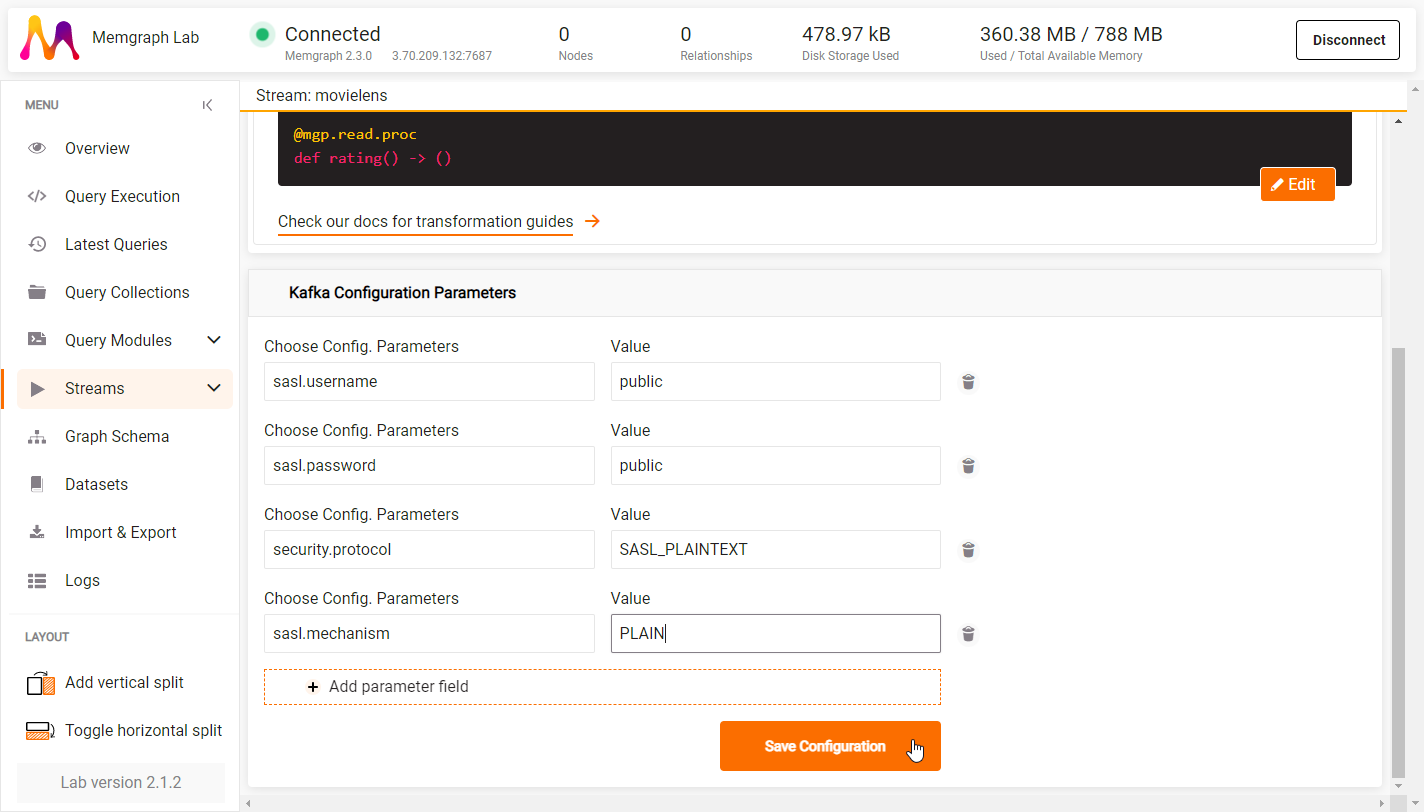
To connect to the Awesome Data Stream you need to set the following Kafka configuration parameters:
- sasl.username: public
- sasl.password: public
- security.protocol: SASL_PLAINTEXT
- sasl.mechanism: PLAIN
Connect Memgraph to the stream and start ingesting the data
Once the stream is configured, you can Connect to Stream.
Memgraph will do a series of checks, ensuring that defined topics and transformation procedures are correctly configured. If all checks pass successfully, you can Start the stream. Once you start the stream, you will no longer be able to change configuration settings, just the transformation module.
The stream status changes to Running and data is ingested into Memgraph. You can see the number of nodes and relationships rising as the data keeps coming in. If your nodes and relationships numbers stay at zero, check the transformation module, as there might be a flaw in the logic that needs to be resolved.
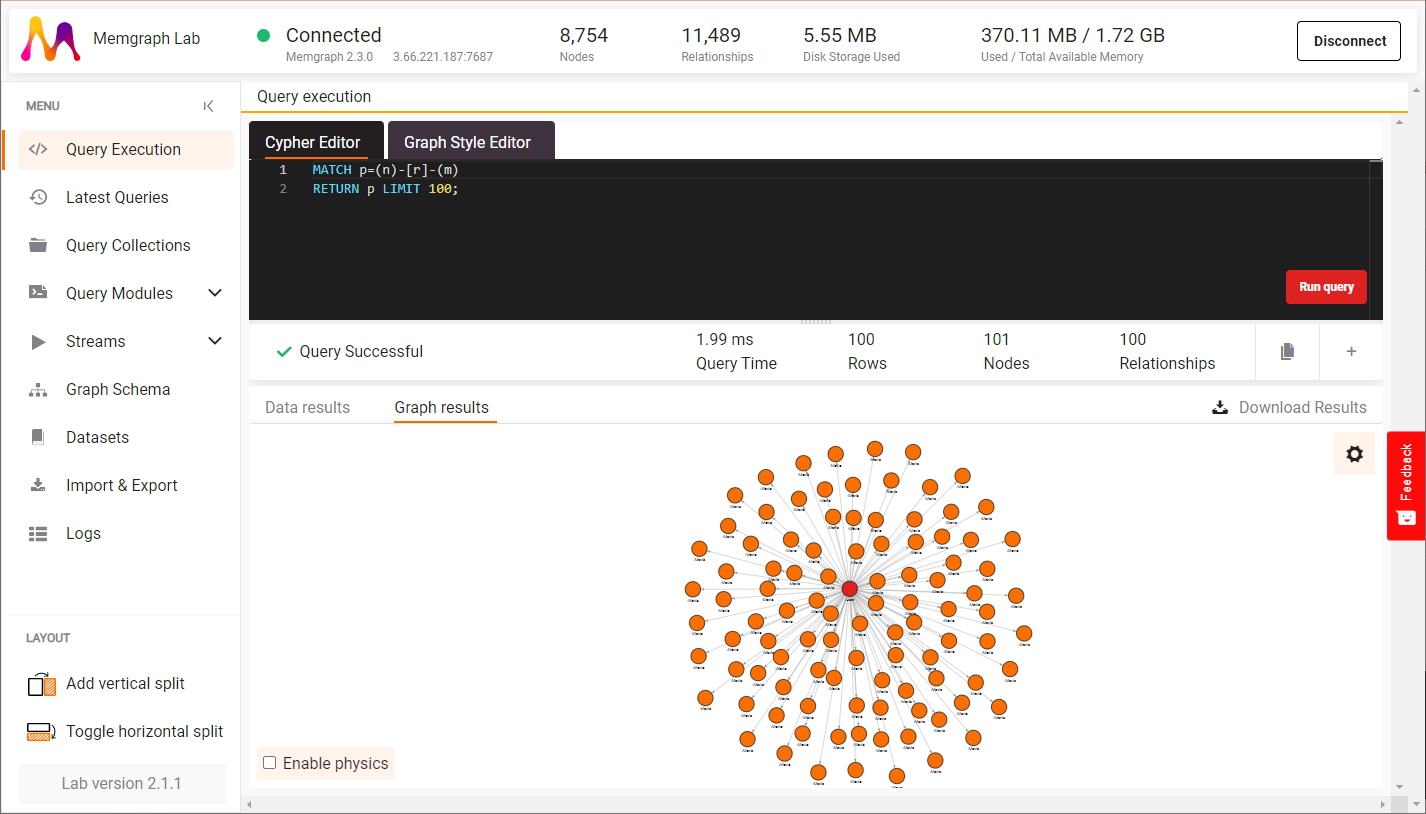
Switch to Query Execution and run a query to visualize the data coming in:
MATCH p=(n)-[r]-(m)
RETURN p LIMIT 100;
Manage a stream
To manage a stream in Memgraph Lab, go to Streams and click on the stream you want to manage (View stream details).
Start, stop, or delete a stream
Position yourself in the stream details view.
To start a draft steam, click Connect to Stream.
To stop or start a stream, click Stop Stream/Start Stream.
To delete a stream, click Delete Stream.
Edit a stream
You cannot edit a started stream. You can only create a new stream with the changes you want to implement.
You can only change the transformation module in the stream details view.
Change Kafka stream offset
Kafka stream offset can be changed only by using a Cypher query.
First stop the stream if it's running, then use the following Cypher query to change Kafka stream offset if necessary and start it again:
CALL mg.kafka_set_stream_offset(streamName, offset)
An offset of -1 denotes the beginning offset available for the given
topic/partition.
An offset of -2 denotes the end of the stream in which case only the
next produced message will be consumed.
Logs
If you are running Memgraph with Docker and want to see logs in Memgraph Lab, be
sure to expose the 7444 port when running the docker run command.
Otherwise, Memgraph's log files can be found at
/var/log/memgraph/memgraph_<date>.log. Look for the name of your stream in the
log file to find the error.
Demo video
As a part of the Memgraph Cloud release, we've showcased different features of Memgraph Lab, for example, how to connect to data streams using Memgraph Lab!
Feel free to check it out:
What's next?
Take a look at the tutorial we made to help you connect Memgraph and Kafka. Learn more about the query power of Cypher language, or check out MAGE - an open-source repository that contains graph algorithms and modules that can help you tackle the most interesting and challenging graph analytics problems.