Graph stream processing with Kafka and Memgraph
In this tutorial, you will learn how to connect Memgraph to an existing Kafka stream in order to analyze data in real-time.
If you are still very new to streaming, feel free to first read some of our blog posts about the topic to learn what stream processing is, how it differs from batch processing and how streaming databases work.
Now that you've covered theory let's dive into practice!
We will focus on processing real-time movie ratings that are streamed through Kafka in order to generate movie recommendations using Memgraph and the Cypher query language.
Prerequisites
To follow this tutorial, you will need:
- Docker
- If you are using Linux, you will also need Docker Compose
- Memgraph Lab - visual user interface that enables you to visualize graphs and execute Cypher queries
- Python
Data model
We didn't want you to worry about setting up Kafka and streaming data, that's why we've prepared a Kafka dummy stream of the reduced MovieLens dataset for you to practice on.
Each JSON message in the stream will be structured like this:
"userId": "112",
"movie": {
"movieId": "4993",
"title": "Lord of the Rings: The Fellowship of the Ring, The (2001)",
"genres": ["Adventure", "Fantasy"]
},
"rating": "5",
"timestamp": "1442535783"
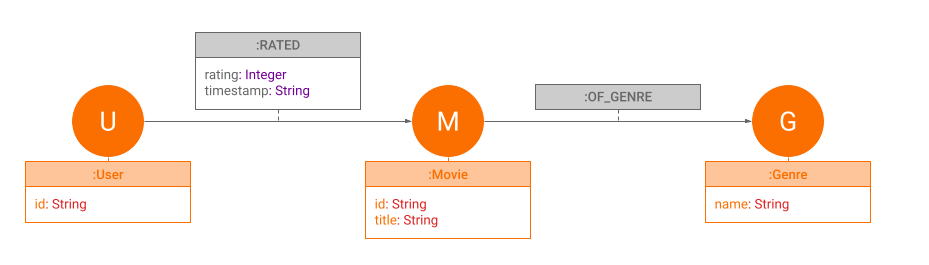
If we were to describe in one sentence the process that generated this data, it would be: "A user rated a movie of a genre". That is how we get the nodes and relationships for our graph data model.
Nodes are labeled User, Movie and Genre while the relationships are of
type RATED or OF_GENRE.
User has the property id, Movie has the properties id and title and
Genre has the property name. RATED has rating (1.0 - 5.0) and
timestamp properties, and OF_GENRE relationship has no properties.
1. Start the Kafka stream
Start by making a clone of the data-streams repository. This project contains the data stream, a Kafka setup and MemgraphDB.
Open a terminal and use the following command:
git clone https://github.com/memgraph/data-streams.git
Now place yourself in the data-streams directory and run the following command
to start the Kafka stream:
python start.py --platforms kafka --dataset movielens
Give the script a couple of minutes, and you should see messages being consumed in the console:
All topics:
['ratings']
Kafka : {'userId': '1', 'movie': {'movieId': '1', 'title': 'Toy Story (1995)', 'genres': ['Adventure', 'Animation', 'Children', 'Comedy', 'Fantasy']}, 'rating': '4.0', 'timestamp': '964982703'}
Kafka : {'userId': '1', 'movie': {'movieId': '3', 'title': 'Grumpier Old Men (1995)', 'genres': ['Comedy', 'Romance']}, 'rating': '4.0', 'timestamp': '964981247'}
Kafka : {'userId': '1', 'movie': {'movieId': '6', 'title': 'Heat (1995)', 'genres': ['Action', 'Crime', 'Thriller']}, 'rating': '4.0', 'timestamp': '964982224'}
Kafka : {'userId': '1', 'movie': {'movieId': '47', 'title': 'Seven (a.k.a. Se7en) (1995)', 'genres': ['Mystery', 'Thriller']}, 'rating': '5.0', 'timestamp': '964983815'}
Kafka : {'userId': '1', 'movie': {'movieId': '50', 'title': 'Usual Suspects, The (1995)', 'genres': ['Crime', 'Mystery', 'Thriller']}, 'rating': '5.0', 'timestamp': '964982931'}
2. Start Memgraph
If we were using a proper Kafka stream, we would start Memgraph independently
using Docker, but because we are using a dummy stream, we will start Memgraph
within the data-streams project. Given that we need to access the data stream
running in a separate Docker container, we need to run Memgraph on the same
network.
Open a new terminal and position yourself in the data-streams directory you
cloned earlier, then build the Memgraph image with the following command:
docker-compose build memgraph-mage
When the image is built, start the container with:
docker-compose up memgraph-mage
You should get the following reply:
Container data-streams-memgraph-mage-1 Created 0.2s
Attaching to data-streams-memgraph-mage-1
data-streams-memgraph-mage-1 | You are running Memgraph v2.1.0
data-streams-memgraph-mage-1 | To get started with Memgraph, visit https://memgr.ph/start
To check if Memgraph is indeed running, open Memgraph Lab and connect to the empty database.
3. Create a transformation module
Before we can connect Memgraph to a data stream, we need to instruct it on how
to transform the incoming messages, so they can be consumed correctly. This is
done through a Python transformation module. If you open the
data-streams/memgraph/transformations/movielens.py you'll see one such
transformation file we've created for this tutorial.
import mgp
import json
@mgp.transformation
def rating(messages: mgp.Messages
) -> mgp.Record(query=str, parameters=mgp.Nullable[mgp.Map]):
result_queries = []
for i in range(messages.total_messages()):
message = messages.message_at(i)
movie_dict = json.loads(message.payload().decode('utf8'))
result_queries.append(
mgp.Record(
query=("MERGE (u:User {id: $userId}) "
"MERGE (m:Movie {id: $movieId, title: $title}) "
"WITH u, m "
"UNWIND $genres as genre "
"MERGE (m)-[:OF_GENRE]->(:Genre {name: genre}) "
"CREATE (u)-[:RATED {rating: ToFloat($rating), timestamp: $timestamp}]->(m)"),
parameters={
"userId": movie_dict["userId"],
"movieId": movie_dict["movie"]["movieId"],
"title": movie_dict["movie"]["title"],
"genres": movie_dict["movie"]["genres"],
"rating": movie_dict["rating"],
"timestamp": movie_dict["timestamp"]}))
return result_queries
Each JSON message triggers a Cypher query that maps the elements of the message as a graph object:
MERGE (u:User {id: $userId})
MERGE (m:Movie {id: $movieId, title: $title})
WITH u, m
UNWIND $genres as genre
MERGE (m)-[:OF_GENRE]->(:Genre {name: genre})
CREATE (u)-[:RATED {rating: ToFloat($rating), timestamp: $timestamp}]->(m)
In the first two line we define two nodes, User and Movie, and define their
properties. If you look at the messages you are receiving from Kafka, you will
notice each movie has several genres. We want to store each genre as a separate
node and that is why we use the UNWIND clause to separate types of genre.
In the last two lines, we create relationships between nodes and define their
properties. Movie nodes belong to a certain Genre, and User nodes rated
Movie nodes by a certain rating in the form of a decimal number (Float) at
a certain time.
4. Copy transformation module into Docker
Once again, the transformation module you will need to complete this tutorial is already locked among the project files so feel free to skip this step and go straight to loading. But hopefully, there will come a time when you will need to create your own transformation modules and you need to know how to copy them into the Docker container.
Let's play around a bit:
Copy the
data-streams/memgraph/transformations/movielens.pyfile to the root directory of your computer and rename itmovielens2.py.Open the file
movielens2.pyand rename the relationshipOF_GENREto justOF:"MERGE (m)-[:OF]->(:Genre {name: genre}) "Open a new terminal and find out the CONTAINER ID of the
memgraph-magecontainer by running:docker psPosition yourself in the root directory (or in the folder where
movielens2.pyfile is) and copy the filemovielens2.pytransformation module to thememgraph-magecontainer by running:docker cp movielens2.py CONTAINER_ID:/usr/lib/memgraph/query_modules/movielens2.pyCheck if you copied the file correctly! Enter the container:
docker exec -it CONTAINER_ID bashList all the files in the
/usr/lib/memgraph/query_modulesfolder and check if themovielens2.pyfile is there:ls /usr/lib/memgraph/query_modules
5. Load the transformation module into Memgraph
Once your transformation module is safe in Docker, you can load it into Memgraph.
All modules are automatically loaded into Memgraph when it starts, but if the module was copied into Docker while the Memgraph was already running, like it was now in step 4, it needs to be loaded by using a Cypher procedure.
You can either use the CALL mg.load_all() procedure to reload all existing
modules and load any newly added ones, or CALL mg.load("module_name") to
(re)load a specific module.
Switch to Memgraph Lab and switch to the Query tab. In the Query editor (the black part of the Lab, looking like a terminal) enter the procedure of your choice and then press Run query to load the transformation module.
I am going to load the original transformation module created for this tutorial
movielens.py:
CALL mg.load("movielens");
If you don’t receive an error, the module was loaded successfully.
6. Connect Memgraph to the Kafka stream
We will connect Memgraph to the Kafka stream by running several queries in Memgraph Lab.
Position yourself in the Query tab and enter the following query into the Query editor (terminal looking area):
CREATE KAFKA STREAM movielens_stream
TOPICS ratings
TRANSFORM movielens.rating
BOOTSTRAP_SERVERS "kafka:9092";In the first line, we gave the stream a custom name, and in the second, we defined the name of the topic we are reading the data from. In the third line we defined the transformation procedure by writing the name of the .py file we are using to transform the data, followed by the function we defined in that file. In the last line we defined the bootstrap servers.
Hit the Run query and if no error appears, you are good to go to the next step.
Now that we have created the stream, it needs to be started in order to consume messages:
START STREAM movielens_stream;To check if the stream was created and started correctly, run the following query:
SHOW STREAMS;
That’s it! You just connected to a real-time data source with Memgraph. If you open the Overview tab in Memgraph Lab, you should see that a number of nodes and edges has already been created.
Just to be sure, open the tab Graph Schema and click on the Generate graph schema button to see if the graph follows the Data model we defined at the beginning of the article.

We are all set to start exploring the data!
7. Analyze the streaming data
We will use Cypher for data analysis, the most popular query language when it comes to graph databases. It provides an intuitive way to work with property graphs.
Let’s return 10 movies from the database:
MATCH (movie:Movie)
RETURN movie.title
LIMIT 10;In the first line, we are matching all
Movienodes and saving them inmovievariable. Then we are return thetitleproperty of those nodes but limiting the result to show only the first 10.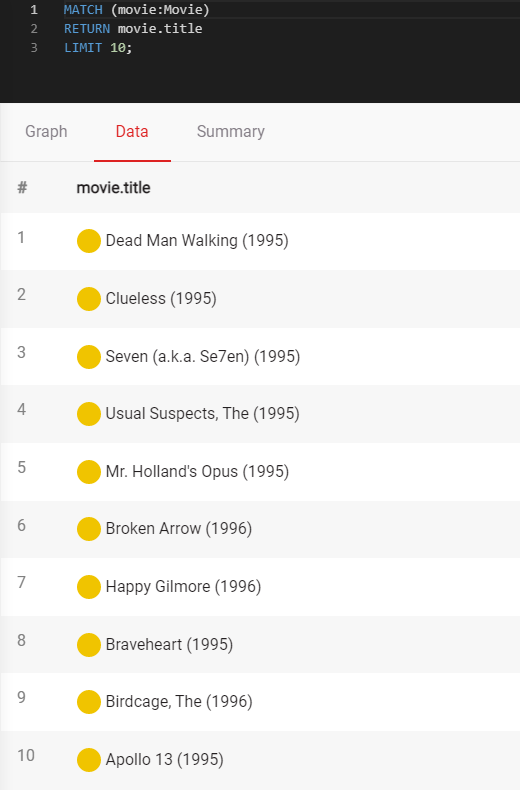
Find Adventure and Fantasy movies:
MATCH (movie:Movie)-[:OF_GENRE]->(:Genre {name:"Fantasy"})
MATCH (movie)-[:OF_GENRE]->(:Genre {name:"Adventure"})
RETURN movie.title
ORDER BY movie.title
LIMIT 10;In the first line, we are matching all
Movienodes of theFantasygenre. Then we are further filtering thoseMovienodes to be of theAdventuregenre as well. The result of this query will be an alphabetized list of 10 movie titles of those two genres.Also, don't worry if the results show less than 10 movies - it just means not enough movies of that genre were received from the stream.

Calculate the average rating score for the movie Matrix:
MATCH (:User)-[r:RATED]->(m:Movie)
WHERE m.title = "Matrix, The (1999)"
RETURN avg(r.rating)We are matching users and their ratings of specific movies. Then we filter only the ratings given to the movie Matrix and return the average rating.
If your result is
null, check your stream for some other movie title and edit the query.
Things will now get a little bit complicated. Let’s find a recommendation for a specific user, for example, with the id 150:
MATCH (u:User {id: "150"})-[r:RATED]-(p:Movie)-[other_r:RATED]-(other:User)
WITH other.id AS other_id, avg(r.rating-other_r.rating) AS similarity
ORDER BY similarity
LIMIT 10
WITH collect(other_id) AS similar_user_set
MATCH (some_movie: Movie)-[fellow_rate:RATED]-(fellow_user:User)
WHERE fellow_user.id IN similar_user_set
WITH some_movie, avg(fellow_rate.rating) AS prediction_score
RETURN some_movie.title AS Title, prediction_score
ORDER BY prediction_score DESC;If you don't get any data using the id 150, check what user IDs you have in your Kafka stream, and just pick one at random. I got data for user ids 144 to 177.
In the first line, we matched all the users who rated the same movie as our user 150.
We got their ids, and then we wanted to filter out only those users who gave the same or similar rating as our user 150. That is why we subtracted their rating scores from the rating scores of user 150 and got an average score. If the result is 0 the users gave the same rating and had a similar taste. As that number grows, users have different tastes.
Then, we ordered the users by the similarity of their taste with the taste of user 150 and collected 10 users into a list called
similar_user_set.With the next
MATCHclause we got all the movies rated by all the users in the database, then filtered the results to get only the movies rated by the users from thesimilar_user_set. We got the average rating score those users gave to a particular movie with the presumption that the user 150 might rate the movie as well, being that he has a similar taste as these 10 users.At the end, we returned the movie titles and prediction score starting with the movie with the highest prediction score.

And that’s it, you have generated recommendations based on the similarity of ratings between users.
Where to next?
Congratulations! You have connected Memgraph to a Kafka stream and analyzed the data. You can continue to do so using the Cypher query language. You can also try using various graph algorithms and modules from our open-source repository MAGE to solve graph analytics problems, create awesome customized visual displays of your nodes and relationships with Graph Style Script and above all - enjoy your graph database!