Migrate from Neo4j to Memgraph
Memgraph is a native in-memory graph database specialized for real-time use-cases such us streaming, analytical processing etc. It uses Cypher query language and Bolt protocol. This means that you can use the same tools and drivers that you are already using with Neo4j. Due to the ACID compliance, data persistency and replication support in community version, Memgraph can be used as main database for your applications, instead of Neo4j.
This tutorial is also available as a video:
Prerequisites
To follow this tutorial, you will need to have the following:
- Running Neo4j instance (with your data, or use the sample data provided)
- Latest
memgraph/memgraph-platformDocker image
Data schema
One of the first steps to consider is how to migrate your data. If you have your data in the form of Cypher queries or CSV or JSON format, you can import these formats into Memgraph. Keep in mind that for importing larger datasets it is recommended to use CSV format or pure Cypher queries (Memgraph's CYPHERL format), since they can be imported into Memgraph natively, faster than JSON format.
This tutorial will go through exporting data from Neo4j into CSV files and importing it into Memgraph using LOAD CSV query and Memgraph's user visual interface Memgraph Lab.
The sample dataset consists of 3 different kinds of nodes (Employee, Order and Product) connected with 3 types of relationships as described by the graph schema below:
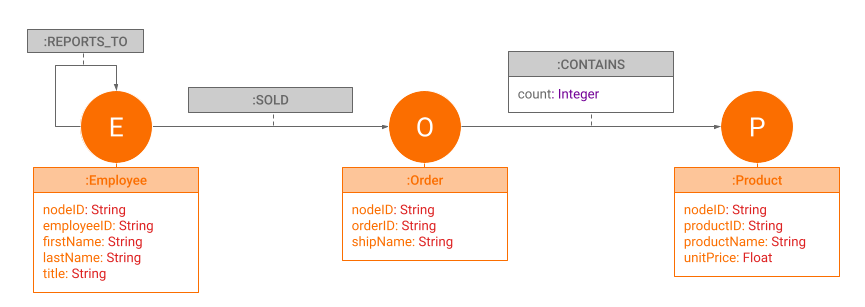
To create this graph in your Neo4j instance run the following queries:
LOAD CSV WITH HEADERS FROM 'https://gist.githubusercontent.com/jexp/054bc6baf36604061bf407aa8cd08608/raw/8bdd36dfc88381995e6823ff3f419b5a0cb8ac4f/orders.csv' AS column
MERGE (order:Order {orderID: column.OrderID})
ON CREATE SET order.shipName = column.ShipName;
LOAD CSV WITH HEADERS FROM 'https://gist.githubusercontent.com/jexp/054bc6baf36604061bf407aa8cd08608/raw/8bdd36dfc88381995e6823ff3f419b5a0cb8ac4f/products.csv' AS column
MERGE (product:Product {productID: column.ProductID})
ON CREATE SET product.productName = column.ProductName, product.unitPrice = toFloat(column.UnitPrice);
LOAD CSV WITH HEADERS FROM 'https://gist.githubusercontent.com/jexp/054bc6baf36604061bf407aa8cd08608/raw/8bdd36dfc88381995e6823ff3f419b5a0cb8ac4f/employees.csv' AS column
MERGE (e:Employee {employeeID:column.EmployeeID})
ON CREATE SET e.firstName = column.FirstName, e.lastName = column.LastName, e.title = column.Title;
CREATE INDEX product_id FOR (p:Product) ON (p.productID);
CREATE INDEX product_name FOR (p:Product) ON (p.productName);
CREATE INDEX employee_id FOR (e:Employee) ON (e.employeeID);
CALL db.awaitIndexes();
LOAD CSV WITH HEADERS FROM 'https://gist.githubusercontent.com/jexp/054bc6baf36604061bf407aa8cd08608/raw/8bdd36dfc88381995e6823ff3f419b5a0cb8ac4f/orders.csv' AS column
MATCH (order:Order {orderID: column.OrderID})
MATCH (product:Product {productID: column.ProductID})
MERGE (order)-[op:CONTAINS]->(product)
ON CREATE SET op.unitPrice = toFloat(column.UnitPrice), op.quantity = toFloat(column.Quantity);
LOAD CSV WITH HEADERS FROM 'https://gist.githubusercontent.com/jexp/054bc6baf36604061bf407aa8cd08608/raw/8bdd36dfc88381995e6823ff3f419b5a0cb8ac4f/orders.csv' AS column
MATCH (order:Order {orderID: column.OrderID})
MATCH (employee:Employee {employeeID: column.EmployeeID})
MERGE (employee)-[:SOLD]->(order);
LOAD CSV WITH HEADERS FROM 'https://gist.githubusercontent.com/jexp/054bc6baf36604061bf407aa8cd08608/raw/8bdd36dfc88381995e6823ff3f419b5a0cb8ac4f/employees.csv' AS column
MATCH (employee:Employee {employeeID: column.EmployeeID})
MATCH (manager:Employee {employeeID: column.ReportsTo})
MERGE (employee)-[:REPORTS_TO]->(manager);
If you are going to use different dataset to migrate, be aware of the
differences between Neo4j and Memgraph data
types (for example, Memgraph doesn't support
DateTime() as there is no temporal type in Memgraph that supports timezones yet,
but you can modify data to use localDateTime()).
Exporting data from Neo4j
Download the CSV file shipping.csv containing the data above if you don't want to go through the exporting process.
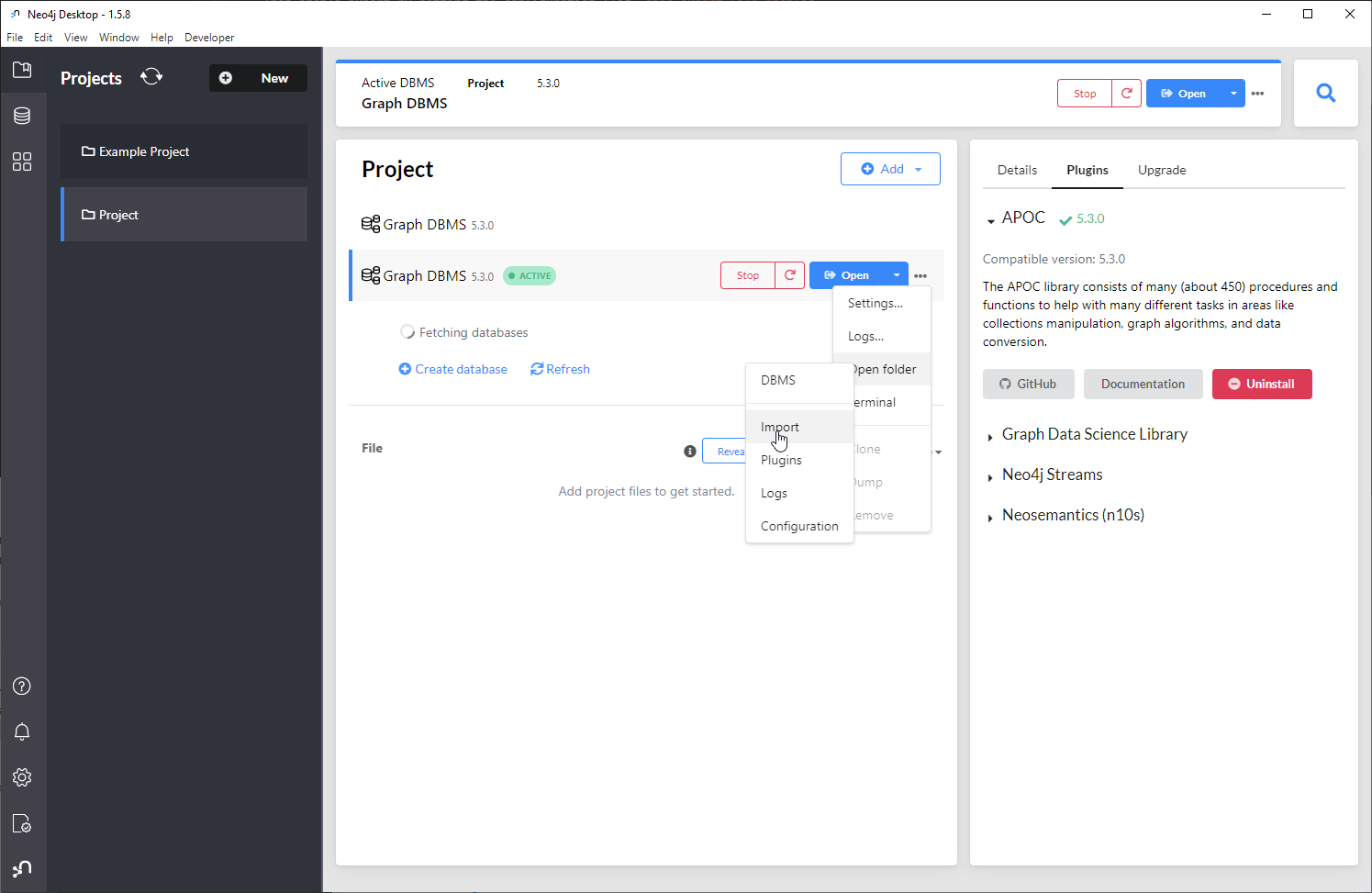
To get your data out of Neo4j instance, use the Neo4j APOC export functionality. To install APOC, select the project, then in the right-side menu select Plugins -> APOC and press install.
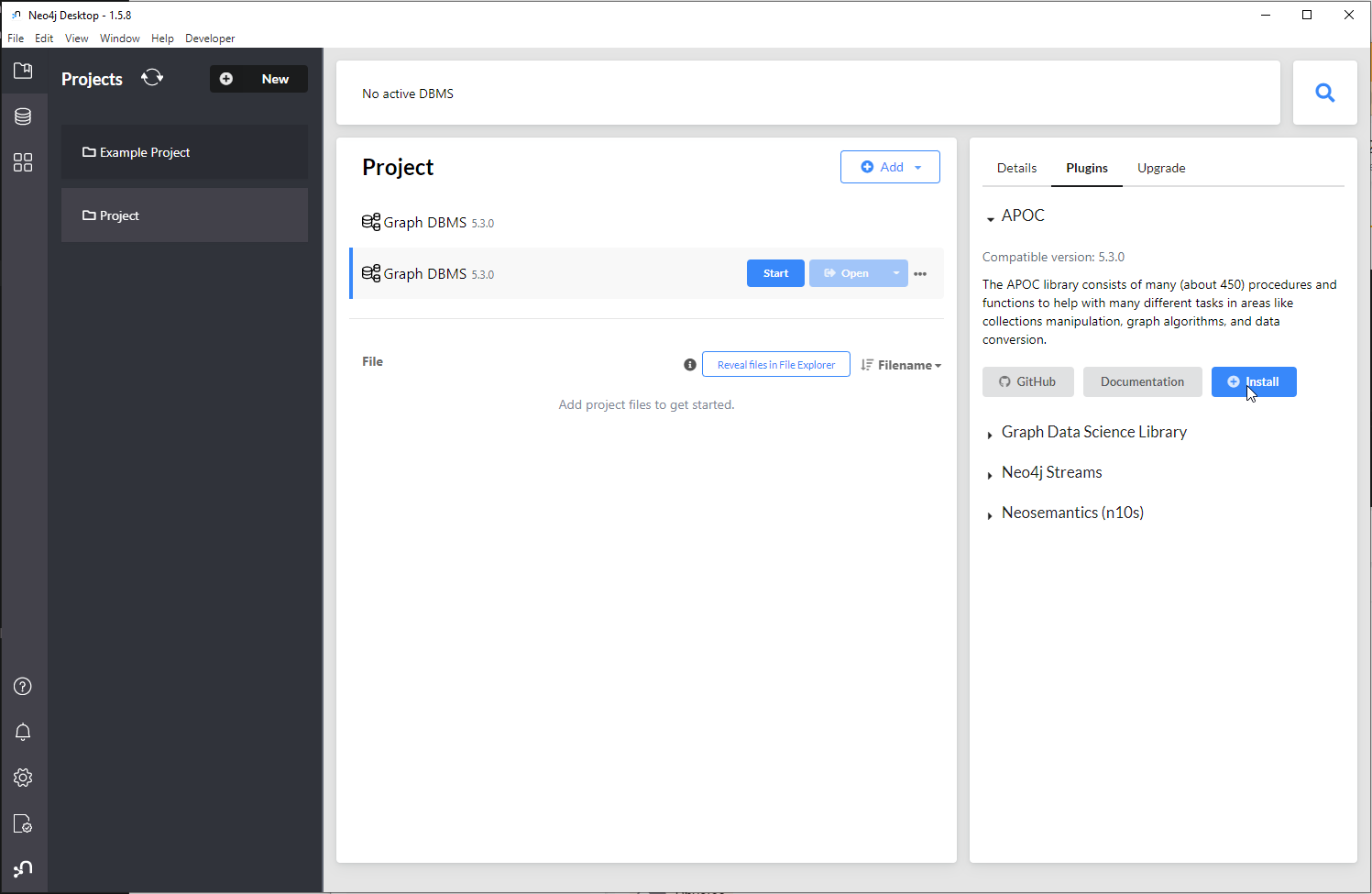
Then enable export by setting the configuration flag apoc.export.file.enabled
to true in the apoc.config file located in the config directory. To open
the directory, select the active project, click on ... -> Open folder ->
Configuration.
Export the data into a CSV file using:
CALL apoc.export.csv.all("shipping.csv", {})
Once exported, the file is located in Neo4j's Import folder. To open it, select the active project, click on ... -> Open folder -> Import.
Importing data into Memgraph
Now that the CSV file containing the needed data has been generated, let's import data into Memgraph.
As the original location of file is quite cumbersome, relocate it somewhere more accessible.
1. Starting Memgraph with Docker
When working with Docker, the file need to be transferred from your local directory into the Docker container where Memgraph can access it.
This can be done by copying the file into your running instance.
Run Memgraph with
docker run -it -p 7687:7687 -p 7444:7444 -p 3000:3000 memgraph/memgraph-platformTo copy the file inside the container, open a new terminal to find out the
CONTAINER IDwithdocker ps, then run:docker cp /path_to_local_folder/shipping.csv <container_ID>:/usr/lib/memgraph/shipping.csvIf the container ID is
bed1e5c9192dand the file is locally located atC:/Datathe command would look like this:docker cp C:/Data/shipping.csv bed1:/usr/lib/memgraph/shipping.csvTo check if the files are inside the container, first run:
docker exec -it CONTAINER_ID bashList the files inside the
/usr/lib/memgraph.C:\Users\Vlasta>docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
bed1e5c9192d memgraph/memgraph-platform "/bin/sh -c '/usr/bi…" 2 minutes ago Up 2 minutes 0.0.0.0:3000->3000/tcp, 0.0.0.0:7444->7444/tcp, 0.0.0.0:7687->7687/tcp recursing_blackburn
C:\Users\Vlasta>docker cp C:/Data/shipping.csv bed1:/usr/lib/memgraph/shipping.csv
C:\Users\Vlasta>docker exec -it bed1 bash
root@bed1e5c9192d:/# ls /usr/lib/memgraph
auth_module memgraph python_support query_modules shipping.csv
root@bed1e5c9192d:/#
2. Gaining speed with indexes and analytical storage mode
Although the dataset imported in this tutorial is quite small, one day you might want to import really big datasets with billions of nodes and relationships and you will require all the extra speed you can get.
To gain speed you can create indexes on the
properties used to connect nodes with relationships which are the values in the
_id column in the CSV files, and in Memgraph they will be named nodeID.
To create indexes, run:
CREATE INDEX ON :Employee(nodeID);
CREATE INDEX ON :Order(nodeID);
CREATE INDEX ON :Product(nodeID);
You can also change the storage mode from
IN_MEMORY_TRANSACTIONAL to IN_MEMORY_ANALYTICAL. This will disable the
creation of durability files (snapshots and WAL files) and you will no longer
have any ACID guarantees. Other transactions will be able to see the changes of
ongoing transactions. Also, transaction will be able to see the changes they are
doing. This means that the transactions can be committed in random orders, and
the updates to the data, in the end, might not be correct.
But, if you import on one thread, batch of data after a batch of data, there should be absolutely no issues, and you will gain 6 times faster import with 6 times less memory consumption.
After import you can switch back to the IN_MEMORY_TRANSACTIONAL storage mode or
continue running analytics queries (only read queries) in the
IN_MEMORY_ANALYTICAL mode to continue benefiting from low memory consumption.
To switch between modes, run the following queries on a running instance:
STORAGE MODE IN_MEMORY_ANALYTICAL;
STORAGE MODE IN_MEMORY_TRANSACTIONAL;
To check the current storage mode, run:
SHOW STORAGE INFO;
Change the storage mode to analytical before import.
STORAGE MODE IN_MEMORY_ANALYTICAL;
3. Importing nodes
To import nodes using a LOAD CSV clause let's examine the clause syntax:
LOAD CSV FROM "csv-file-path.csv" ( WITH | NO ) HEADER [IGNORE BAD] [DELIMITER <delimiter-string>] [QUOTE <quote-string>] AS <variable-name>
The file is now located at /usr/lib/memgraph/shipping.csv and it has a header
row. There is no need to ignore bad rows, the default deliminator is , and
the default quote character ", the same as in the exported CSV file, so no
changes are necessary.
The first row of the LOAD CSV clause therefore looks like this:
LOAD CSV FROM "/usr/lib/memgraph/shipping.csv" WITH HEADER AS row
Nodes are always imported before relationships so they will be imported first.
The shipping.csv file contains the following columns important for node
creation: _id, labels, employeeID, firstName, lastName, orderID,
productID, productName, shipName, title, unitPrice.
The _id property is actually an internal node ID needed to create
relationships later on.
Execute queries in Memgraph Lab. Open your browser and go to
http://localhost:3000/, Connect now to the instance and go to the Query
Execution section.
Employee nodes
Begin with Employee nodes.
After establishing the location and format of the CSV file, filter out the rows
that contain the label :Employee:
LOAD CSV FROM "/usr/lib/memgraph/shipping.csv" WITH HEADER AS row
WITH row WHERE row._labels = ':Employee'
Then, create nodes with a certain label and properties. As an example, let's
look at the property _id. To add the property to the node, define its name in
Memgraph and assigned the value of a specific column in the CSV file.
LOAD CSV FROM "/usr/lib/memgraph/shipping.csv" WITH HEADER AS row
WITH row WHERE row._labels = ':Employee'
CREATE (e:Employee {nodeID: row._id})
So nodeID: row._id part of the query instructs Memgraph to create a property
named nodeID and assign it the value paired with key _id. First created
node will be assigned the value from the first data row, second node from the
second data row, etc.
After matching up the keys and values for all properties, the finished query looks like this:
LOAD CSV FROM "/usr/lib/memgraph/shipping.csv" WITH HEADER AS row
WITH row WHERE row._labels = ':Employee'
CREATE (e:Employee {nodeID: row._id, employeeID: row.employeeID, firstName: row.firstName, lastName: row.lastName, title: row.title});
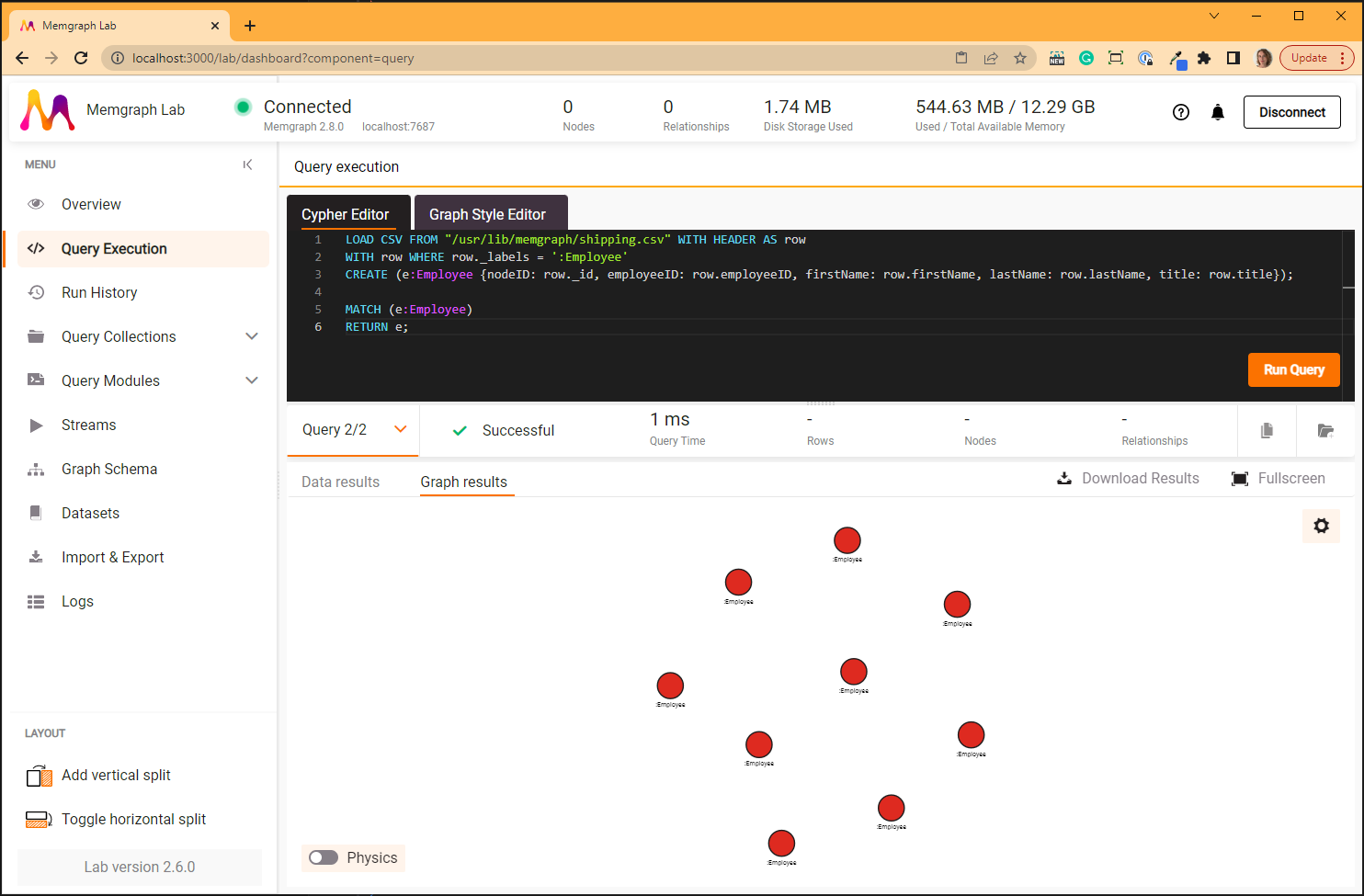
MATCH (e:Employee)
RETURN e;
The second query will show all 9 created nodes.
Copy the query in the Cypher Editor and Run Query.
Order nodes
Relevant properties for the Order nodes are _id, orderID and shipName.
To create Order nodes run the following query:
LOAD CSV FROM "/usr/lib/memgraph/shipping.csv" WITH HEADER AS row
WITH row WHERE row._labels = ':Order'
CREATE (o:Order {nodeID: row._id, orderID: row.orderID, shipName: row.shipName});
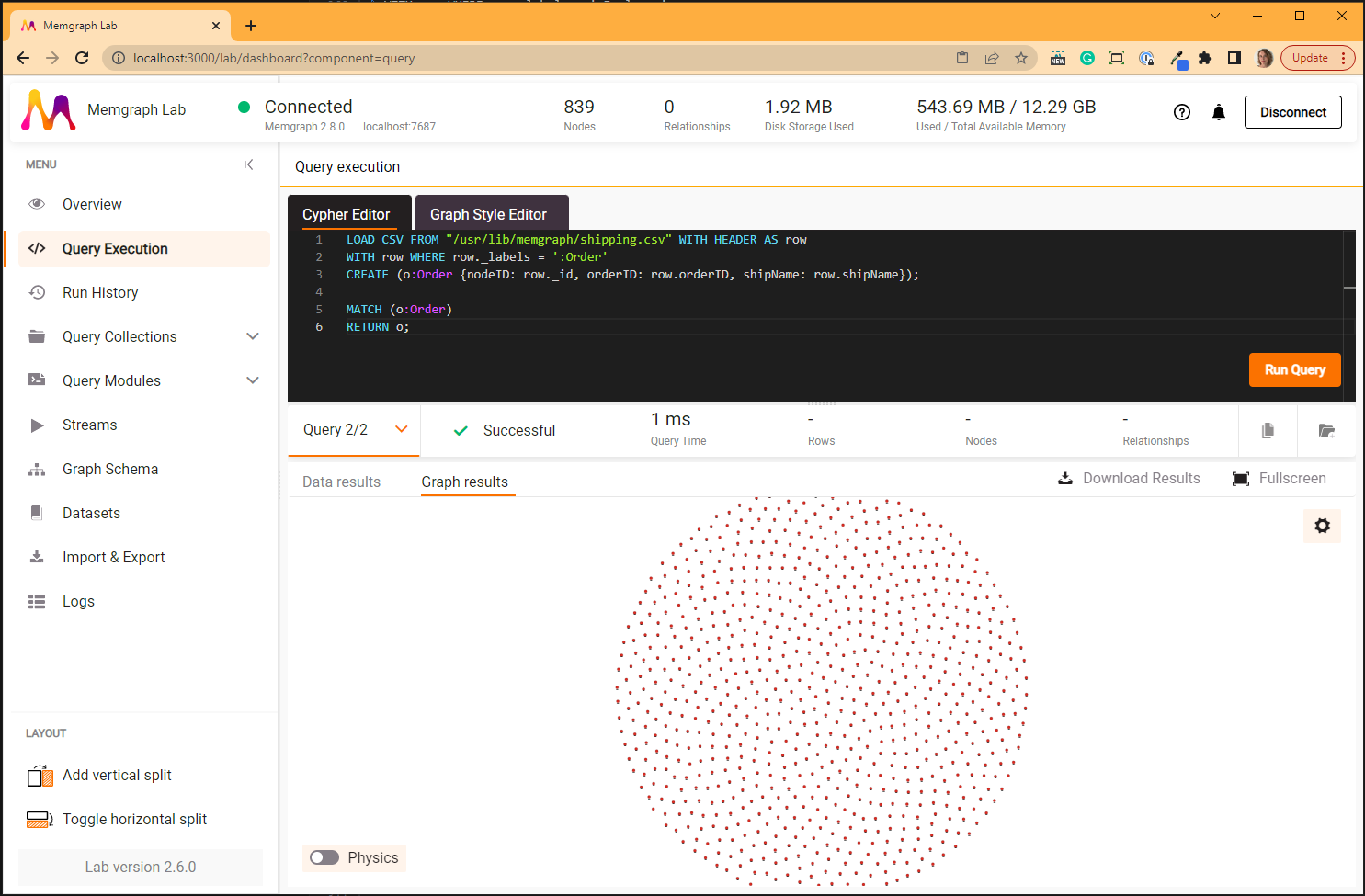
MATCH (o:Order)
RETURN o;
The second query will show all 830 created nodes:
Product nodes
Relevant properties for the Product nodes are _id, productID, productName
and unitPrice.
As the parser parses all the values as strings, and the unitPrice are numbers,
they need to be converted to appropriate data type.
To create Product nodes run the following query:
LOAD CSV FROM "/usr/lib/memgraph/shipping.csv" WITH HEADER AS row
WITH row WHERE row._labels = ':Product'
CREATE (p:Product {nodeID: row._id, productID: row.productID, productName: row.productName, unitPrice: ToFloat(row.unitPrice)});
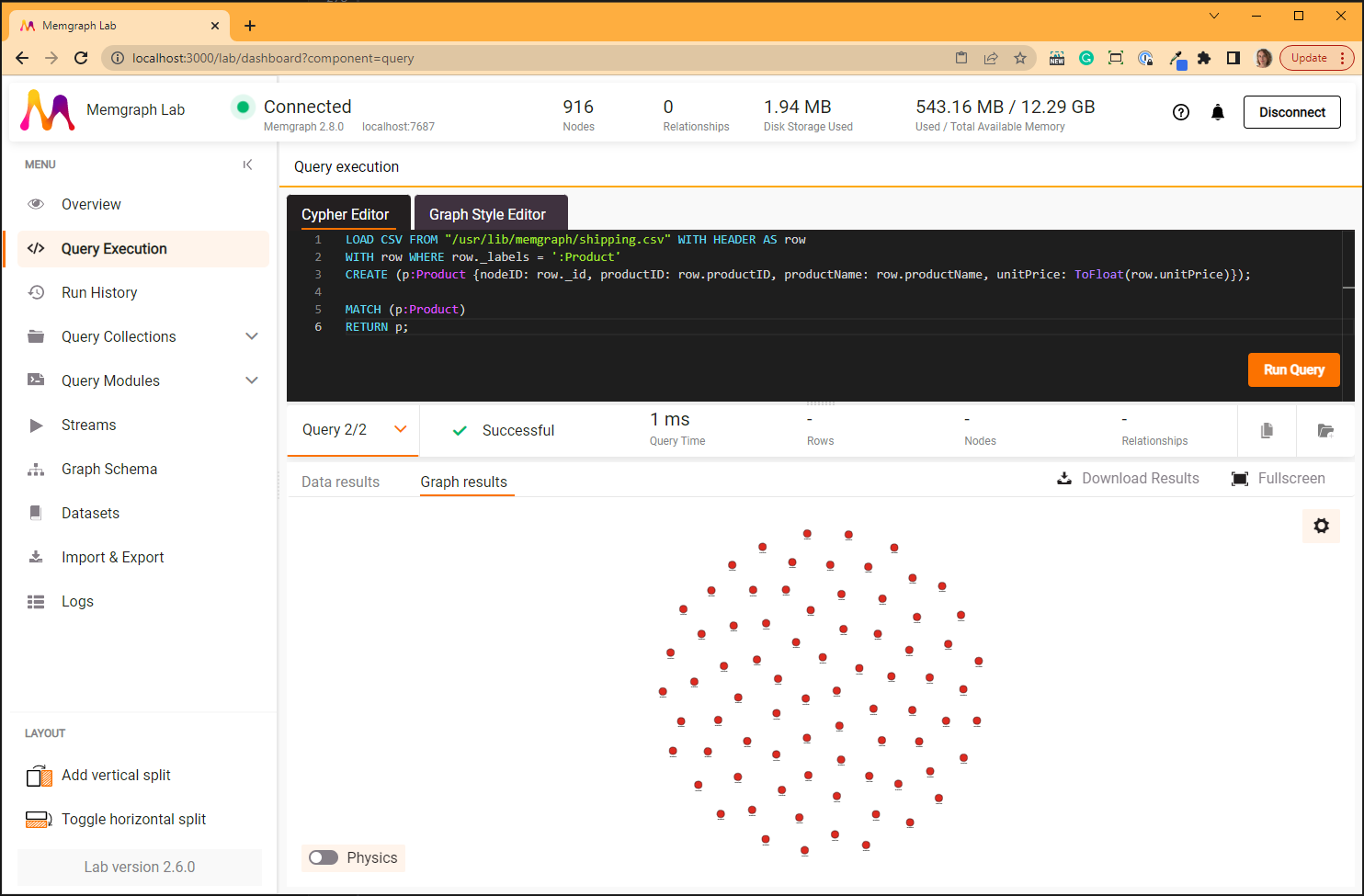
MATCH (p:Product)
RETURN p;
The second query will show all 77 created nodes:
4. Graph improvements
At this point it would be nice to improve the look of the nodes visually. At the moment, nodes in the graph are represented with their labels, but it would be more useful if their name attribute was written.
To adjust the look of the graph using Graph Style Language, open the Graph Style Editor. Find the following code block:
@NodeStyle HasProperty(node, "name") {
label: AsText(Property(node, "name"))
}
It defines that if the node has the property name, its label on the visual
graph will be that property.
As none of the imported nodes have the property name, this part of the code
needs to be adjusted to use the properties nodes do have.
Replace those three lines of code with the following block and Apply the changes:
@NodeStyle HasProperty(node, "firstName") {
label: AsText(Property(node, "firstName"))
}
@NodeStyle HasProperty(node, "orderID") {
label: AsText(Property(node, "orderID"))
}
@NodeStyle HasProperty(node, "productName") {
label: AsText(Property(node, "productName"))
}
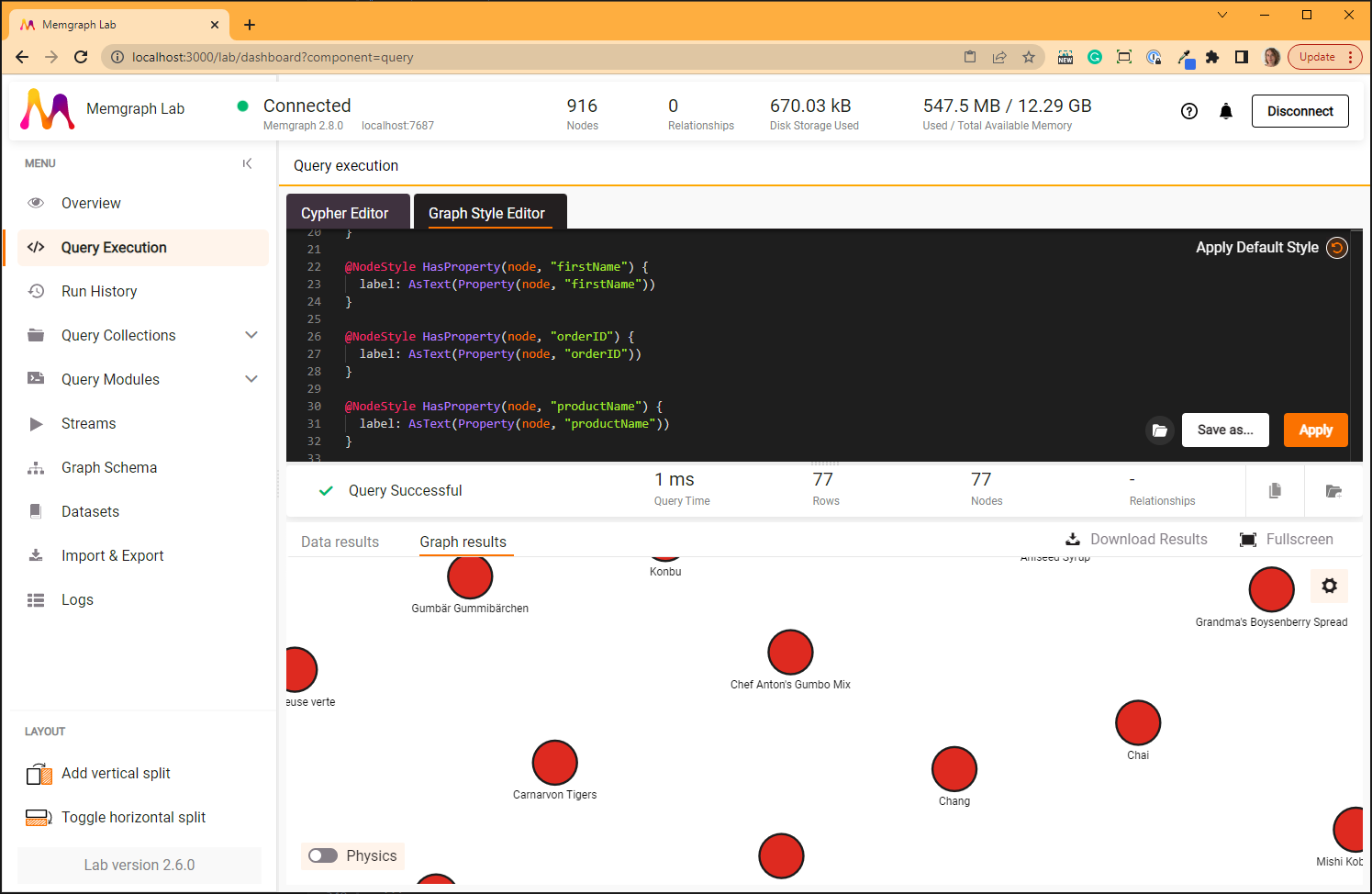
Visual appearance of the graph can be changed in many different ways, so be sure to check the GSS documentation.
5. Importing relationships
Now that all the 916 nodes have been imported, they can be connected with relationships.
The first row of the LOAD CSV remains the same:
LOAD CSV FROM "/usr/lib/memgraph/shipping.csv" WITH HEADER AS row
The shipping.csv file contains the following values important for relationship
creation: _type, _start, _end, quantity and unitPrice.
The _type defines relationships type, _start and _end values define which
nodes need to be connected based on their ID.
:REPORTS_TO relationships
Begin with :REPORTS_TO relationship.
After establishing the location and format of the CSV file, filter out the rows
that contain the type REPORTS_TO:
LOAD CSV FROM "/usr/lib/memgraph/shipping.csv" WITH HEADER AS row
WITH row WHERE row._type = 'REPORTS_TO'
Now instruct Memgraph to find the nodes with certain IDs in order to create a
relationship between them. As node IDs are unique we can just define that any
node with a certain ID is a starting point, and another node with a certain ID
is the end point of the relationship type REPORTS_TO.
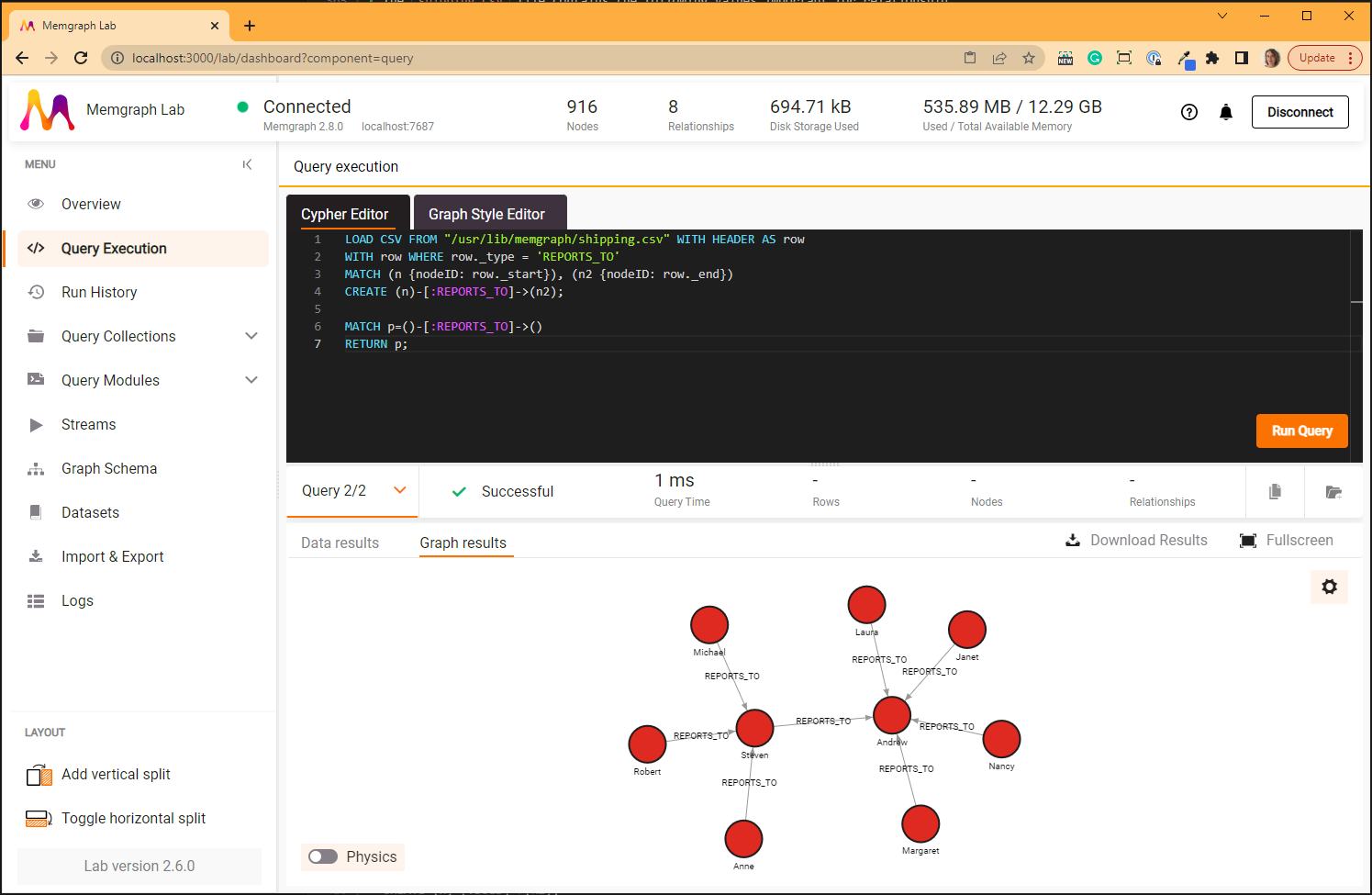
The LOAD CSV query creates 8 :REPORTS_TO relationships:
LOAD CSV FROM "/usr/lib/memgraph/shipping.csv" WITH HEADER AS row
WITH row WHERE row._type = 'REPORTS_TO'
MATCH (n {nodeID: row._start}), (n2 {nodeID: row._end})
CREATE (n)-[:REPORTS_TO]->(n2);
MATCH p=()-[:REPORTS_TO]->()
RETURN p;
The second query returns all the nodes connected with the REPORTS_TO type of
relationship.
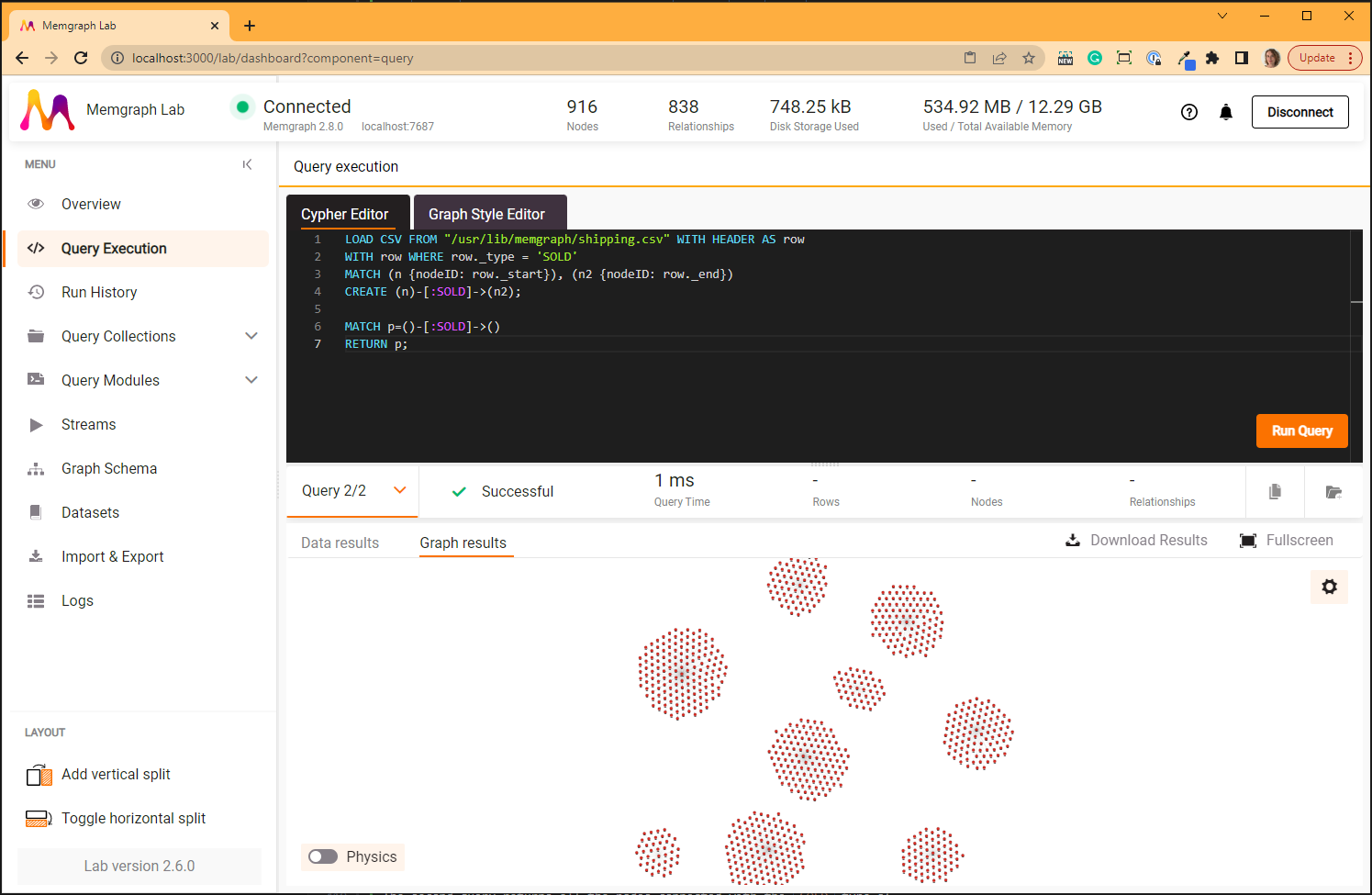
:SOLD relationships
The LOAD CSV query creates 830 :SOLD relationships:
LOAD CSV FROM "/usr/lib/memgraph/shipping.csv" WITH HEADER AS row
WITH row WHERE row._type = 'SOLD'
MATCH (n {nodeID: row._start}), (n2 {nodeID: row._end})
CREATE (n)-[:SOLD]->(n2);
MATCH p=()-[:SOLD]->()
RETURN p;
The second query returns all the nodes connected with the SOLD type of
relationship.
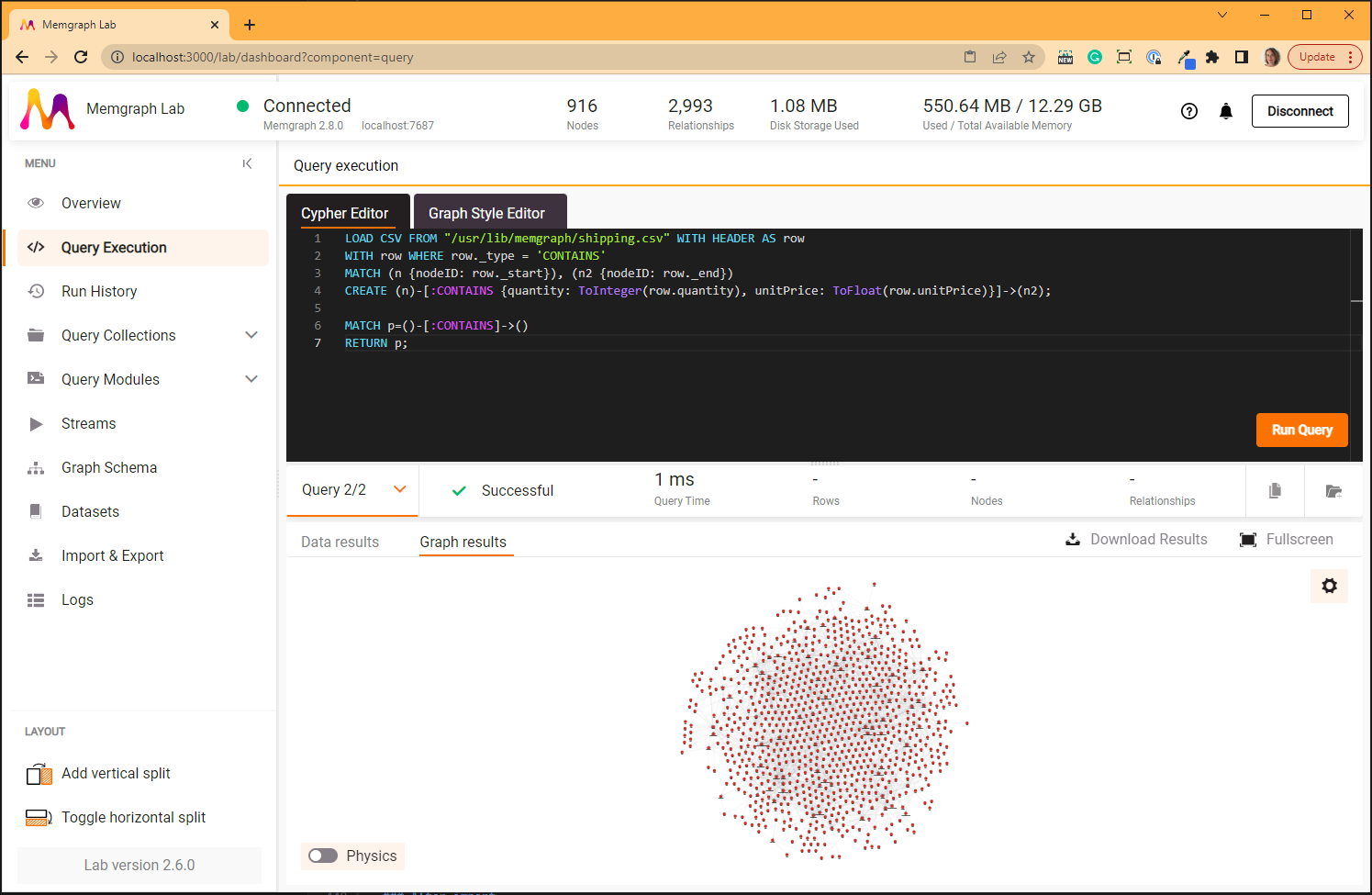
:CONTAINS relationships
This relationship type has properties about the quantity of products one order
contains.
As the parser parses all the values as strings, and the value of this relationship property are numbers, they need to be converted to appropriate type.
The LOAD CSV query creates 2155 CONTAINS relationships:
LOAD CSV FROM "/usr/lib/memgraph/shipping.csv" WITH HEADER AS row
WITH row WHERE row._type = 'CONTAINS'
MATCH (n {nodeID: row._start}), (n2 {nodeID: row._end})
CREATE (n)-[:CONTAINS {quantity: ToInteger(row.quantity)}]->(n2);
MATCH p=()-[:CONTAINS]->()
RETURN p;
The second query returns all the nodes connected with the CONTAINS type of
relationship.
After import
Once all the 916 nodes and 2993 relationships have been imported decide whether you want to switch back to the transactional storage mode or not. Remember that the analytical storage mode you are using right now has no ACID compliance.
To switch back to the analytical storage mode, run:
STORAGE MODE IN_MEMORY_TRANSACTIONAL;
To check the switch was successful, run:
SHOW STORAGE INFO;
You can query the database using the Cypher query language, use various graph algorithms and modules from our open-source repository MAGE to solve graph analytics problems, create awesome customized visual displays of your nodes and relationships with Graph Style Script, find out how to connect any streams of data you might have with Memgraph and above all - enjoy your new graph database!